
 719 お客様のコメント
719 お客様のコメント
質問 1:
For each input key-value pair, mappers can emit:
A. One intermediate key-value pair, of a different type.
B. As many intermediate key-value pairs as designed, as long as all the keys have the same types and all the values have the same type.
C. As many intermediate key-value pairs as designed. There are no restrictions on the types of those key-value pairs (i.e., they can be heterogeneous).
D. As many intermediate key-value pairs as designed, but they cannot be of the same type as the input key-value pair.
E. One intermediate key-value pair, but of the same type.
正解:B
解説: (Pass4Test メンバーにのみ表示されます)
質問 2:
You've written a MapReduce job that will process 500 million input records and generated 500 million key-value pairs. The data is not uniformly distributed. Your MapReduce job will create a significant amount of intermediate data that it needs to transfer between mappers and reduces which is a potential bottleneck. A custom implementation of which interface is most likely to reduce the amount of intermediate data transferred across the network?
A. Combiner
B. OutputFormat
C. Writable
D. InputFormat
E. Partitioner
F. WritableComparable
正解:A
解説: (Pass4Test メンバーにのみ表示されます)
質問 3:
Which one of the following is NOT a valid Oozie action?
A. hive
B. pig
C. mrunit
D. mapreduce
正解:C
質問 4:
Indentify which best defines a SequenceFile?
A. A SequenceFile contains a binary encoding of an arbitrary number of WritableComparable objects, in sorted order.
B. A SequenceFile contains a binary encoding of an arbitrary number of heterogeneous Writable objects
C. A SequenceFile contains a binary encoding of an arbitrary number key-value pairs. Each key must be the same type. Each value must be the same type.
D. A SequenceFile contains a binary encoding of an arbitrary number of homogeneous Writable objects
正解:C
解説: (Pass4Test メンバーにのみ表示されます)
質問 5:
Assuming the following Hive query executes successfully:
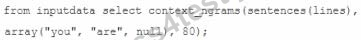
Which one of the following statements describes the result set?
A. A bigram of the top 80 sentences that contain the substring "you are" in the lines column of the input data A1 table.
B. A trigram of the top 80 sentences that contain "you are" followed by a null space in the lines column of the inputdata table.
C. An 80-value ngram of sentences that contain the words "you" or "are" in the lines column of the inputdata table.
D. A frequency distribution of the top 80 words that follow the subsequence "you are" in the lines column of the inputdata table.
正解:D
質問 6:
Which project gives you a distributed, Scalable, data store that allows you random, realtime read/write access to hundreds of terabytes of data?
A. Hive
B. HBase
C. Hue
D. Flume
E. Pig
F. Sqoop
G. Oozie
正解:B
解説: (Pass4Test メンバーにのみ表示されます)
質問 7:
What types of algorithms are difficult to express in MapReduce v1 (MRv1)?
A. Relational operations on large amounts of structured and semi-structured data.
B. Text analysis algorithms on large collections of unstructured text (e.g, Web crawls).
C. Algorithms that require global, sharing states.
D. Algorithms that require applying the same mathematical function to large numbers of individual binary records.
E. Large-scale graph algorithms that require one-step link traversal.
正解:C
解説: (Pass4Test メンバーにのみ表示されます)
質問 8:
You are developing a MapReduce job for sales reporting. The mapper will process input keys representing the year (IntWritable) and input values representing product indentifies (Text).
Indentify what determines the data types used by the Mapper for a given job.
A. The InputFormat used by the job determines the mapper's input key and value types.
B. The key and value types specified in the JobConf.setMapInputKeyClass and JobConf.setMapInputValuesClass methods
C. The mapper-specification.xml file submitted with the job determine the mapper's input key and value types.
D. The data types specified in HADOOP_MAP_DATATYPES environment variable
正解:A
解説: (Pass4Test メンバーにのみ表示されます)
質問 9:
You want to Ingest log files Into HDFS, which tool would you use?
A. HCatalog
B. Flume
C. Sqoop
D. Ambari
正解:B
For each input key-value pair, mappers can emit:
A. One intermediate key-value pair, of a different type.
B. As many intermediate key-value pairs as designed, as long as all the keys have the same types and all the values have the same type.
C. As many intermediate key-value pairs as designed. There are no restrictions on the types of those key-value pairs (i.e., they can be heterogeneous).
D. As many intermediate key-value pairs as designed, but they cannot be of the same type as the input key-value pair.
E. One intermediate key-value pair, but of the same type.
正解:B
解説: (Pass4Test メンバーにのみ表示されます)
質問 2:
You've written a MapReduce job that will process 500 million input records and generated 500 million key-value pairs. The data is not uniformly distributed. Your MapReduce job will create a significant amount of intermediate data that it needs to transfer between mappers and reduces which is a potential bottleneck. A custom implementation of which interface is most likely to reduce the amount of intermediate data transferred across the network?
A. Combiner
B. OutputFormat
C. Writable
D. InputFormat
E. Partitioner
F. WritableComparable
正解:A
解説: (Pass4Test メンバーにのみ表示されます)
質問 3:
Which one of the following is NOT a valid Oozie action?
A. hive
B. pig
C. mrunit
D. mapreduce
正解:C
質問 4:
Indentify which best defines a SequenceFile?
A. A SequenceFile contains a binary encoding of an arbitrary number of WritableComparable objects, in sorted order.
B. A SequenceFile contains a binary encoding of an arbitrary number of heterogeneous Writable objects
C. A SequenceFile contains a binary encoding of an arbitrary number key-value pairs. Each key must be the same type. Each value must be the same type.
D. A SequenceFile contains a binary encoding of an arbitrary number of homogeneous Writable objects
正解:C
解説: (Pass4Test メンバーにのみ表示されます)
質問 5:
Assuming the following Hive query executes successfully:
Which one of the following statements describes the result set?
A. A bigram of the top 80 sentences that contain the substring "you are" in the lines column of the input data A1 table.
B. A trigram of the top 80 sentences that contain "you are" followed by a null space in the lines column of the inputdata table.
C. An 80-value ngram of sentences that contain the words "you" or "are" in the lines column of the inputdata table.
D. A frequency distribution of the top 80 words that follow the subsequence "you are" in the lines column of the inputdata table.
正解:D
質問 6:
Which project gives you a distributed, Scalable, data store that allows you random, realtime read/write access to hundreds of terabytes of data?
A. Hive
B. HBase
C. Hue
D. Flume
E. Pig
F. Sqoop
G. Oozie
正解:B
解説: (Pass4Test メンバーにのみ表示されます)
質問 7:
What types of algorithms are difficult to express in MapReduce v1 (MRv1)?
A. Relational operations on large amounts of structured and semi-structured data.
B. Text analysis algorithms on large collections of unstructured text (e.g, Web crawls).
C. Algorithms that require global, sharing states.
D. Algorithms that require applying the same mathematical function to large numbers of individual binary records.
E. Large-scale graph algorithms that require one-step link traversal.
正解:C
解説: (Pass4Test メンバーにのみ表示されます)
質問 8:
You are developing a MapReduce job for sales reporting. The mapper will process input keys representing the year (IntWritable) and input values representing product indentifies (Text).
Indentify what determines the data types used by the Mapper for a given job.
A. The InputFormat used by the job determines the mapper's input key and value types.
B. The key and value types specified in the JobConf.setMapInputKeyClass and JobConf.setMapInputValuesClass methods
C. The mapper-specification.xml file submitted with the job determine the mapper's input key and value types.
D. The data types specified in HADOOP_MAP_DATATYPES environment variable
正解:A
解説: (Pass4Test メンバーにのみ表示されます)
質問 9:
You want to Ingest log files Into HDFS, which tool would you use?
A. HCatalog
B. Flume
C. Sqoop
D. Ambari
正解:B







幸岩** -
Apache-Hadoop-Developerの知識としてもこの本を真面目に勉強すれば合格点を取れると思い、余裕でApache-Hadoop-Developerに受かりました!!