
 563 お客様のコメント
563 お客様のコメント
質問 1:
You need to run the same job many times with minor variations. Rather than hardcoding all job
configuration options in your drive code, you've decided to have your Driver subclass
org.apache.hadoop.conf.Configured and implement the org.apache.hadoop.util.Tool interface.
Indentify which invocation correctly passes.mapred.job.name with a value of Example to Hadoop?
A. hadoop setproperty mapred.job.name=Example MyDriver input output
B. hadoop MyDrive -D mapred.job.name=Example input output
C. hadoop "mapred.job.name=Example" MyDriver input output
D. hadoop MyDriver mapred.job.name=Example input output
E. hadoop setproperty ("mapred.job.name=Example") MyDriver input output
正解:B
質問 2:
For each input key-value pair, mappers can emit:
A. One intermediate key-value pair, of a different type.
B. As many intermediate key-value pairs as designed, but they cannot be of the same type as the input
key-value pair.
C. As many intermediate key-value pairs as designed. There are no restrictions on the types of those
key-value pairs (i.e., they can be heterogeneous).
D. One intermediate key-value pair, but of the same type.
E. As many intermediate key-value pairs as designed, as long as all the keys have the same types and all
the values have the same type.
正解:E
質問 3:
What is the term for the process of moving map outputs to the reducers?
A. Partitioning
B. Shuffling and sorting
C. Reducing
D. Combining
正解:B
質問 4:
Given the following Pig commands:

Which one of the following statements is true?
A. The $1 variable represents the first column of data in 'my.log'
B. The $1 variable represents the second column of data in 'my.log'
C. The grouped relation is not valid
D. The severe relation is not valid
正解:B
質問 5:
In a MapReduce job, the reducer receives all values associated with same key. Which statement best
describes the ordering of these values?
A. The values are in sorted order.
B. The values are arbitrary ordered, but multiple runs of the same MapReduce job will always have the
same ordering.
C. Since the values come from mapper outputs, the reducers will receive contiguous sections of sorted
values.
D. The values are arbitrarily ordered, and the ordering may vary from run to run of the same MapReduce
job.
正解:D
質問 6:
Given the following Hive command:
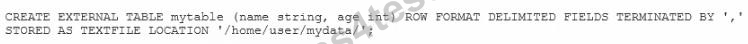
Which one of the following statements is true?
A. The files in the mydata folder are moved to a subfolder of /apps/hive/wa re house
B. The files in the mydata folder do not move from their current location In HDFS
C. The files in the mydata folder are copied into Hive's underlying relational database
D. The files in the mydata folder are copied to a subfolder of /apps/hlve/warehouse
正解:B
質問 7:
To process input key-value pairs, your mapper needs to lead a 512 MB data file in memory. What is the
best way to accomplish this?
A. Serialize the data file, insert in it the JobConf object, and read the data into memory in the configure
method of the mapper.
B. Place the data file in the DataCache and read the data into memory in the configure method of the
mapper.
C. Place the data file in the DistributedCache and read the data into memory in the map method of the
mapper.
D. Place the data file in the DistributedCache and read the data into memory in the configure method of
the mapper.
正解:B
You need to run the same job many times with minor variations. Rather than hardcoding all job
configuration options in your drive code, you've decided to have your Driver subclass
org.apache.hadoop.conf.Configured and implement the org.apache.hadoop.util.Tool interface.
Indentify which invocation correctly passes.mapred.job.name with a value of Example to Hadoop?
A. hadoop setproperty mapred.job.name=Example MyDriver input output
B. hadoop MyDrive -D mapred.job.name=Example input output
C. hadoop "mapred.job.name=Example" MyDriver input output
D. hadoop MyDriver mapred.job.name=Example input output
E. hadoop setproperty ("mapred.job.name=Example") MyDriver input output
正解:B
質問 2:
For each input key-value pair, mappers can emit:
A. One intermediate key-value pair, of a different type.
B. As many intermediate key-value pairs as designed, but they cannot be of the same type as the input
key-value pair.
C. As many intermediate key-value pairs as designed. There are no restrictions on the types of those
key-value pairs (i.e., they can be heterogeneous).
D. One intermediate key-value pair, but of the same type.
E. As many intermediate key-value pairs as designed, as long as all the keys have the same types and all
the values have the same type.
正解:E
質問 3:
What is the term for the process of moving map outputs to the reducers?
A. Partitioning
B. Shuffling and sorting
C. Reducing
D. Combining
正解:B
質問 4:
Given the following Pig commands:
Which one of the following statements is true?
A. The $1 variable represents the first column of data in 'my.log'
B. The $1 variable represents the second column of data in 'my.log'
C. The grouped relation is not valid
D. The severe relation is not valid
正解:B
質問 5:
In a MapReduce job, the reducer receives all values associated with same key. Which statement best
describes the ordering of these values?
A. The values are in sorted order.
B. The values are arbitrary ordered, but multiple runs of the same MapReduce job will always have the
same ordering.
C. Since the values come from mapper outputs, the reducers will receive contiguous sections of sorted
values.
D. The values are arbitrarily ordered, and the ordering may vary from run to run of the same MapReduce
job.
正解:D
質問 6:
Given the following Hive command:
Which one of the following statements is true?
A. The files in the mydata folder are moved to a subfolder of /apps/hive/wa re house
B. The files in the mydata folder do not move from their current location In HDFS
C. The files in the mydata folder are copied into Hive's underlying relational database
D. The files in the mydata folder are copied to a subfolder of /apps/hlve/warehouse
正解:B
質問 7:
To process input key-value pairs, your mapper needs to lead a 512 MB data file in memory. What is the
best way to accomplish this?
A. Serialize the data file, insert in it the JobConf object, and read the data into memory in the configure
method of the mapper.
B. Place the data file in the DataCache and read the data into memory in the configure method of the
mapper.
C. Place the data file in the DistributedCache and read the data into memory in the map method of the
mapper.
D. Place the data file in the DistributedCache and read the data into memory in the configure method of
the mapper.
正解:B






Satou -
アプリバージョン最高でした。しっかりHADOOP-PR000007の問題覚えられるから。隙間時間にも学習が進められる。